From October 15th to today, all our users are reporting extremely bad meeting conditions on both audio and video.
Obviously (we investigated) this is coming from Zoon network and not from our users environment.
Most of those users are doing 1 to 1 meeting, with the host (and the meeting) passing by a gateway on a Region A, and the other participant (non host) joining through a gateway located on a Region B.
A and B being Tokyo and Hong Kong since its the two closest region to reply to web sdk pings from Japan. (hello Singapore, are you still there ?)
Very sorry that this is happening! Our team is currently investigating what could be a cause here; however, I have increased the urgency to move things along faster. At the moment, we don’t have a concrete answer to give you, but as we know more, we will let you know.
@tommy can support and update you from here, but I wanted to jump in and let you know it’s been escalated. (ZOOM-199643)
After additional searches, it seems that chrome version (85.0.4183.133) on chrome OS was in cause here, plus a potential latency issue introduced by the gateway story - stacking with the first problem.
We removed HK and upgraded the chrome version to latest one and situation is much better.
We still would like you to investigate about the gateway story. Until now, even when a user is passing by a different region, it is for both DC and gateway, not a different region for DC and gateway.
Was this a problem specific to HK ?
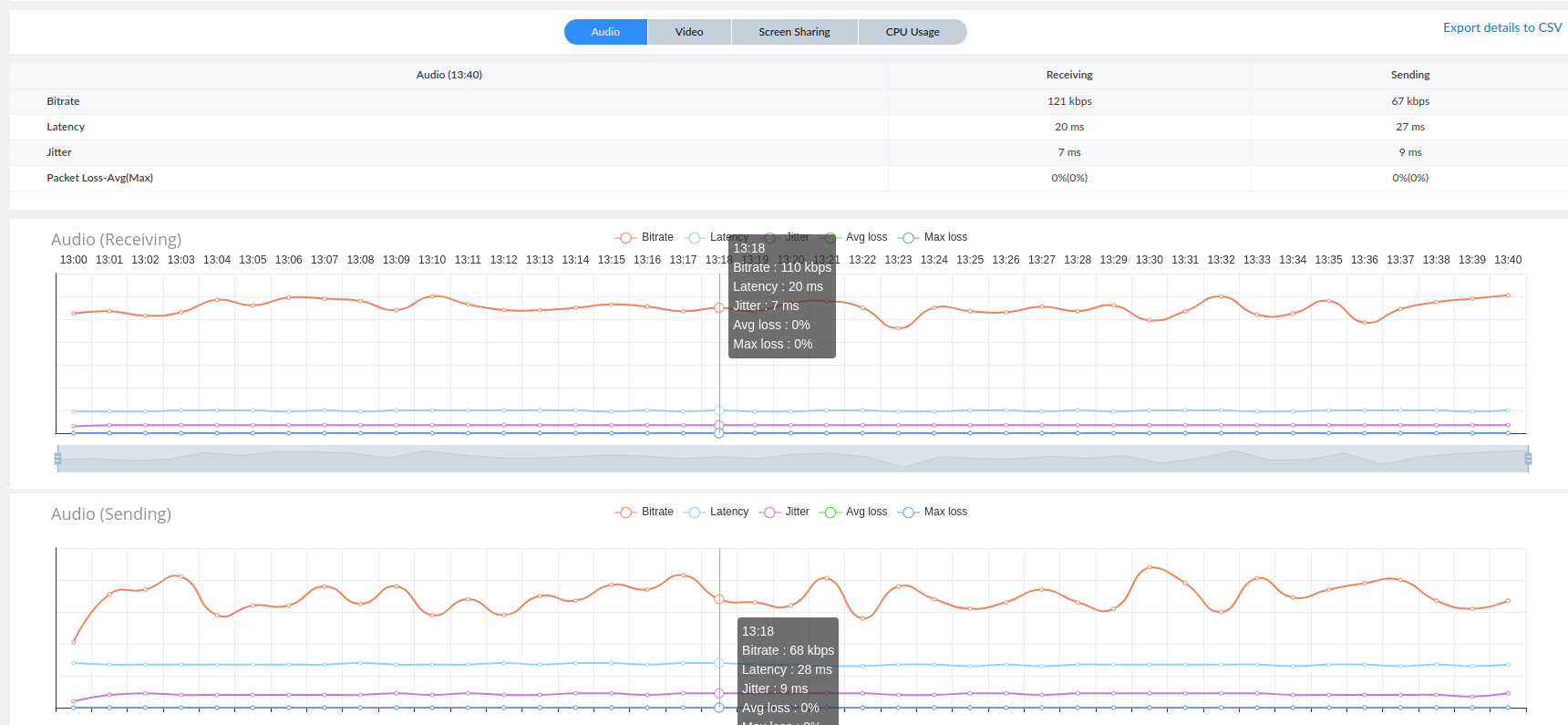
Every time a user join through a gateway (RWG) located in a different place than the data center (Top), users reports bad audio quality.
When you look at the audio metrics for that connection, we can see systematic latency on both sending and receiving channels:
We switched off Hong Kong last Friday, so now we are mainly redirected to US. I could notice the same behavior time to time.
Here is an example, having the gateway in DV and data center in SC
Again, latency introduced but looks like it’s lower and not have a noticeable impact on the audio.
Happy to hear you were able to resolve some of the issues.
We are still investigating the gateway story. Thanks for sharing the additional info and graphs. This will help us to find the root cause. I will keep you updated on what we find, and how we plan to fix it.